
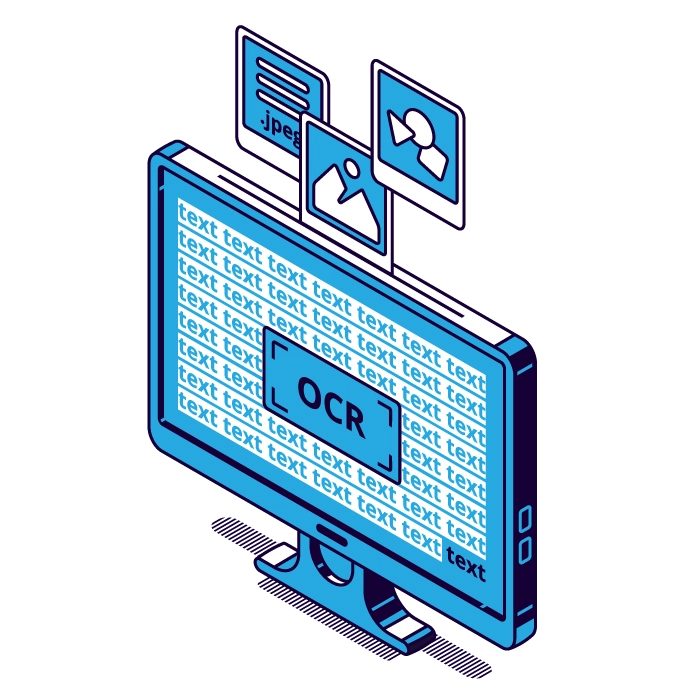
OCR (Optical Character Recognition) คือ เทคโนโลยีการรู้จำตัวอักษรด้วยแสง ที่ใช้แปลงข้อความบนรูปภาพ เอกสารสแกน หรือไฟล์ PDF ให้กลายเป็นข้อความดิจิทัลที่แก้ไข ค้นหา และคัดลอกไปใช้งานต่อได้ทันที โดยไม่ต้องพิมพ์ใหม่ด้วยมือ องค์กรในไทยนิยมใช้ OCR ลดงานคีย์ข้อมูลจากใบแจ้งหนี้ ใบเสร็จ และเอกสารนำเข้า-ส่งออก ซึ่งช่วยลดเวลาทำงานได้มากกว่า 80% และลดข้อผิดพลาดจากการกรอกข้อมูลด้วยมือ (Human Error) ได้เกือบทั้งหมด
ในบทความนี้ทีมงาน KSP AsiaFIN ผู้ให้บริการระบบ OCR และ RPA สำหรับองค์กรในประเทศไทย จะพาไปรู้จักว่า OCR ทำงานอย่างไร มีกี่ประเภท ใช้กับไฟล์อะไรได้บ้าง พร้อมตัวอย่างการใช้งานจริงในธุรกิจไทย

หลักการทำงานของ OCR แบ่งเป็น 4 ขั้นตอนหลัก ดังนี้
💡 ระบบ OCR สมัยใหม่อย่าง OrangeVision Form+ รองรับ ภาษาไทย ได้แม่นยำสูง แม้เป็นเอกสารที่มีวรรณยุกต์และสระซับซ้อน — อ่านรายละเอียดที่ OCR ภาษาไทย
OCR แบ่งออกเป็น 3 ประเภทหลักตามความสามารถในการอ่านเอกสาร ธุรกิจสามารถเลือกใช้ตามลักษณะเอกสารที่ต้องจัดการ
เหมาะสำหรับแปลงข้อความตัวพิมพ์มาตรฐานจากเอกสารที่มีรูปแบบชัดเจน เช่น รายงานทางธุรกิจ หนังสือ คู่มือการใช้งาน หรือสัญญา เหมาะกับเอกสารคุณภาพดี ไม่มีรอยขีดเขียนหรือรอยขีดฆ่า
หรือ Intelligent Document Processing พัฒนาต่อจาก Simple OCR ด้วย AI และ Machine Learning สามารถเข้าใจ “โครงสร้าง” ของเอกสาร เช่น รู้ว่าตรงไหนคือเลขที่ใบแจ้งหนี้ วันที่ หรือยอดเงิน จึงดึงเฉพาะข้อมูลที่ต้องการจากแบบฟอร์มและตารางได้ ไม่ใช่แค่แปลงทั้งหน้าเป็นข้อความ
ออกแบบมาเพื่อแปลงข้อความลายมือเป็นข้อมูลดิจิทัลโดยเฉพาะ เหมาะกับเอกสารที่กรอกด้วยมือ เช่น แบบฟอร์มราชการ บันทึกการประชุม หรือเอกสารทางการแพทย์
ภาษาไทยเป็นหนึ่งในภาษาที่ OCR อ่านยากที่สุด เพราะ:
วิธีแก้คือใช้ AI OCR ที่ฝึกด้วยชุดข้อมูลภาษาไทยโดยตรง อย่าง OrangeVision Form+ ซึ่งพัฒนาร่วมกันโดยทีมไทย-มาเลเซีย รองรับเอกสารราชการและเอกสารบัญชีภาษาไทยโดยเฉพาะ ความแม่นยำสูงกว่า 95% และมีระบบให้ผู้ใช้ตรวจทาน-แก้ไขก่อนส่งข้อมูลเข้าระบบ (Human-in-the-loop)
ใช้ดึงข้อความจากภาพถ่ายหรือไฟล์ภาพ เช่น ใบเสร็จ บัตรประชาชน หรือเอกสารที่ถ่ายด้วยมือถือ รองรับไฟล์ JPG, PNG, TIFF และ BMP — ดูขั้นตอนละเอียดได้ที่ วิธีแปลงรูปเป็นข้อความ
ตัวอย่างการใช้กับรูปภาพ:
เทคนิคเตรียมภาพให้ OCR อ่านแม่นขึ้น:
ไฟล์ PDF ที่ได้จากการสแกนคือ “รูปภาพ” ที่ค้นหาข้อความไม่ได้ OCR ช่วยเปลี่ยนให้เป็น Searchable PDF ที่ค้นหา คัดลอก และแก้ไขได้ — อ่านวิธีใช้งานละเอียดที่ OCR PDF
ตัวอย่างการใช้กับไฟล์ PDF:
จุดที่องค์กรได้ประโยชน์สูงสุดคือการใช้ OCR ร่วมกับ RPA — OCR อ่านข้อมูลจากเอกสาร แล้ว RPA นำข้อมูลไปจัดเรียงลงไฟล์ Excel หรือกรอกเข้าระบบ ERP/บัญชีให้อัตโนมัติ 100% เหมาะกับงานบัญชี คลังสินค้า และงานเอกสารปริมาณมาก — ดูตัวอย่างที่ แปลง PDF เป็น Excel
สแกนและแปลงสัญญา หนังสือมอบอำนาจ และคำสั่งศาลเป็นไฟล์ดิจิทัล ค้นหาข้อความสำคัญได้ในไม่กี่วินาที
อ่านและจัดเก็บข้อมูลจากเอกสารทะเบียนราษฎร์ บัตรประชาชน หนังสือเดินทาง และกระดาษคำตอบแบบปรนัย
เลือกจากเกณฑ์ 5 ข้อนี้:

| เครื่องมือ | จุดเด่น | เหมาะกับ |
|---|---|---|
| OrangeVision Form+ | OCR ภาษาไทยแม่นยำสูง ดึงข้อมูลจากฟอร์ม/ตาราง ทำงานร่วมกับ RPA ได้ทันที มีทีมซัพพอร์ตไทย | องค์กรไทยที่ต้องการระบบครบวงจร |
| Google Cloud Vision | AI แม่นยำ รองรับหลายภาษา | นักพัฒนาที่เชื่อม API เอง |
| Adobe Acrobat OCR | แปลง PDF ง่าย ใช้แพร่หลาย | งานเอกสารทั่วไปรายบุคคล |
| Tesseract | ฟรี โอเพนซอร์ส | นักพัฒนา ทดลองใช้งาน |
| Microsoft Azure AI Vision | ผูกกับระบบ Microsoft | องค์กรที่ใช้ Azure อยู่แล้ว |
| Amazon Textract | ดึงข้อมูลฟอร์ม/ตารางบน AWS | องค์กรที่ใช้ AWS อยู่แล้ว |
สนใจดูจุดเด่นแบบเจาะลึกและตัวอย่างการใช้งานจริง อ่านต่อที่ โปรแกรม OCR สำหรับองค์กร
OCR แปลงเอกสารเป็นข้อมูล แต่ความคุ้มค่าที่แท้จริงเกิดเมื่อข้อมูลนั้น “ไหลต่อ” เข้าระบบโดยไม่ต้องใช้คน เช่น อ่านใบแจ้งหนี้ → ตรวจสอบความถูกต้อง → กรอกเข้าระบบบัญชี → ตั้งหนี้อัตโนมัติ → แจ้งเตือนผู้อนุมัติ ทั้งหมดนี้ทำได้ด้วย OCR + โปรแกรม RPA — ดูภาพรวมการทำงานร่วมกันที่ RPA + OCR Automation
ปรึกษาฟรี: ทีม KSP AsiaFIN ยินดีประเมินว่าเอกสารแบบไหนขององค์กรคุณใช้ OCR ได้ และคุ้มค่าแค่ไหน
📞 084-324-2749 • 📧 info@kspasiafin.com • ติดต่อเรา
หากองค์กรของคุณพร้อมนำ OCR ไปใช้กับเอกสารจริง ดูรายละเอียด โปรแกรม OCR ภาษาไทยสำหรับองค์กร และขอ Demo ฟรีเพื่อทดสอบกับเอกสารขององค์กรคุณได้ทันที
OCR ย่อมาจาก Optical Character Recognition ภาษาไทยเรียกว่า “การรู้จำตัวอักษรด้วยแสง” คือเทคโนโลยีที่แปลงข้อความบนภาพหรือเอกสารสแกนให้เป็นข้อความดิจิทัล
เครื่องมือฟรี (เช่น Google Lens, Tesseract) เหมาะกับงานทั่วไปครั้งคราว แต่ OCR ระดับองค์กรดึงข้อมูลเฉพาะฟิลด์จากแบบฟอร์มได้ ประมวลผลเอกสารปริมาณมากแบบตั้งค่าครั้งเดียว เชื่อมต่อระบบบัญชี/ERP ได้ และมีมาตรการความปลอดภัยข้อมูลที่ตรวจสอบได้
ขึ้นอยู่กับคุณภาพเอกสารและเครื่องมือที่ใช้ OCR ทั่วไปมักมีปัญหากับสระและวรรณยุกต์ไทย แต่ AI OCR ที่ฝึกด้วยข้อมูลภาษาไทยโดยตรง เช่น OrangeVision Form+ ให้ความแม่นยำได้สูงกว่า 95% กับเอกสารคุณภาพดี
OCR อ่านตัวอักษรพิมพ์จากภาพ ส่วน ICR (Intelligent Character Recognition) เป็นเวอร์ชันที่ฉลาดขึ้น สามารถอ่านลายมือและเรียนรู้รูปแบบการเขียนของแต่ละบุคคลได้
ได้ — OCR ระดับองค์กรอย่าง OrangeVision Form+ สามารถเข้าใจโครงสร้างตาราง แยกข้อมูลแต่ละช่อง และส่งออกเป็นไฟล์ Excel ที่จัดเรียงตามคอลัมน์ได้ทันที
เริ่มจาก (1) เลือกกระบวนการที่มีเอกสารปริมาณมากและรูปแบบค่อนข้างคงที่ เช่น ใบแจ้งหนี้ (2) ทดสอบความแม่นยำกับเอกสารจริง (3) กำหนดขั้นตอนตรวจทาน และ (4) เชื่อมต่อข้อมูลเข้าระบบปลายทางด้วย RPA — ติดต่อทีม KSP AsiaFIN เพื่อขอ Demo ฟรีได้ที่ 084-324-2749